title: 简单且高度可扩展的分布式文件系统SeaweedFS
copyright: true
date: 2020-03-06 16:08:21
tags: [SeaweedFS,分布式,文件系统]
categories: 技术栈
0x00 概述

Github: https://github.com/chrislusf/seaweedfs
SeaweedFS is a simple and highly scalable distributed file system, to store and serve billions of files fast! SeaweedFS implements an object store with O(1) disk seek, transparent cloud integration, and an optional Filer with POSIX interface, supporting S3 API, Rack-Aware Erasure Coding for warm storage, FUSE mount, Hadoop compatible, WebDAV.
SeaweedFS是一个简单且高度可扩展的分布式文件系统,可以快速存储和提供数十亿个文件!SeaweedFS通过 O(1) 磁盘搜索,透明云集成以及带有POSIX接口的可选Filer,实现了对象存储,支持S3 API,用于热存储的机架感知擦除编码,FUSE安装,Hadoop兼容,WebDAV。
0x01 基础概念
随着业务量增长,一个系统需要存储上百万文件的情况越来越多,尤其是互联网网站。在这种情况下依然使用传统磁盘/共享存储的方式进行支持会有以下问题:
-
文件的备份、恢复困难,大量文件的copy 耗时耗力
-
文件数量暴增占满操作系统文件系统inode,导致磁盘空间虽然没有用完但是因为inode用尽无法使用
-
文件读取效率太低,无法应对高并发读取要求
针对以上问题,facebook 提出了自己的方案 Facebook’s Haystack design paper 。 之后各种实现出现,如tfs、MogileFS、GlusterFS等,其中Seaweedfs是一个比较优秀的实现。具有效率高、结构简单、代码清晰等优点。
在逻辑上Seaweedfs的几个概念:
| 概念 | 解释 |
|---|---|
| Node | 系统抽象的节点,抽象为DataCenter、Rack、DataNode |
| DataCenter | 数据中心,对应现实中的不同机房 |
| Rack | 机架,对应现实中的机柜 |
| Datanode | 存储节点,用于管理、存储逻辑卷,其实就是Volume server(卷服务器),而Volume server下是有很多个逻辑卷的 |
| Volume | 逻辑卷,存储的逻辑结构,逻辑卷下存储Needle |
| Needle | 逻辑卷中的Object,对应存储的文件(每个文件有一个唯一needleID) |
| Collection | 文件集,可以分布在多个逻辑卷上 |
结构说明:

0x02 组成部分
-
基础部分:Master server + Volume server
-
扩展部分:Filer server + Cronjob server (Replication-job) + S3 server
值得注意的一点:外部与 Master Server、Volume Server 和 Filer 进行通信的方式是 HTTP API。API的用法官网有详细说明。
部署结构:

0x03 快速上手
从 https://github.com/chrislusf/seaweedfs/releases 下载最新版本
解压缩下载的文件,只会找到一个可执行文件,在大多数系统上是“ weed”,在Windows上是“ weed.exe”。
./weed -h # to check available options
配置运行Weed Master server
./weed master -h # to check available options
如果不需要复制,就足够了。mdir选项用于配置保存生成的序列文件ID的文件夹。
./weed master -mdir="."
./weed master -mdir="." -ip=xxx.xxx.xxx.xxx # usually set the ip instead the default "localhost"
配置运行Weed Volume Server
./weed volume -h # to check available options
通常,卷服务器分布在不同的服务器上。它们可以具有不同的磁盘空间,甚至可以具有不同的操作系统。
通常,你需要指定可用磁盘空间,Weed Master地址和存储文件夹。
./weed volume -max=100 -mserver="localhost:9333" -dir="./data"
PS:设置一台Weed Master server和一台Weed Volume Server,可以用weed server简写:
./weed server -dir="./data"
# same, just specifying the default values
# use "weed server -h" to find out more
./weed server -master.port=9333 -volume.port=8080 -dir="./data"
测试SeaweedFS
随着主服务器和卷服务器的启动,现在呢?让我们将大量文件注入系统!
./weed upload -dir="/some/big/folder"
此命令将以递归方式上载所有文件。或者,您可以指定要包括的文件。
./weed upload -dir="/some/big/folder" -include=*.txt
然后,您只需检查“ du -m -s / some / big / folder”即可查看操作系统的实际磁盘使用情况,并将其与“ / data”下的文件大小进行比较。通常,如果您要上传大量文本文件,则消耗的磁盘大小会小得多,因为文本文件会自动压缩。
0x04 在docker中使用
与docker一起使用很容易,因为它在本地运行,您可以像上面那样传递所有args。但是您不必担心“ -ip”。入口点脚本将对其进行处理。
docker run -p 9333:9333 --name master chrislusf/seaweedfs master -ip=master
docker run -p 8080:8080 -p 18080:18080 --name volume --link master chrislusf/seaweedfs volume -max=5 -mserver="master:9333" -port=8080
使用compose
但是使用Compose最简单。要启动,只需运行:
docker-compose -f docker/seaweedfs-compose.yml -p seaweedfs up
您可以使用映像“ chrislusf / seaweedfs”或在根目录中使用dockerfile构建自己的映像。
docker run --name weed chrislusf/seaweedfs server
从dockerfile构建image
git clone https://github.com/chrislusf/seaweedfs.git
docker build --no-cache -t 'chrislusf/seaweedfs' .
构建docker image
mv Dockerfile Dockerfile.minimal
mv Dockerfile.go_build Dockerfile
docker build --no-cache -t 'chrislusf/seaweedfs' .
生产使用
# start our weed server daemonized
docker run --name weed -d -p 9333:9333 -p 8080:8080 -p 18080:8080 \
-v /opt/weedfs/data:/data chrislusf/seaweedfs server -dir="/data" \
-publicIp="$(curl -s cydev.ru/ip)"
现在,SeaweedFS服务器将是持久性的,并且可以通过主机上的localhost:9333,:8080和:18080进行访问。不要忘记为指定正确的“ -publicIp”。
0x05 组成部分介绍
Master Server
Master是不存储数据的,只做集群协调,类似于Zookeeper的作用。
Master Server API 详见 https://github.com/chrislusf/seaweedfs/wiki/Master-Server-API
Tips:可以使用&pretty = y附加到任何HTTP API,以查看格式化的json输出。
分配一个fileId,用于接下来的存储文件
# Basic Usage:
curl http://localhost:9333/dir/assign
{"count":1,"fid":"3,01637037d6","url":"127.0.0.1:8080",
"publicUrl":"localhost:8080"}
# To assign with a specific replication type:
curl "http://localhost:9333/dir/assign?replication=001"
# To specify how many file ids to reserve
curl "http://localhost:9333/dir/assign?count=5"
# To assign a specific data center
curl "http://localhost:9333/dir/assign?dataCenter=dc1"
查询
curl "http://localhost:9333/dir/lookup?volumeId=3&pretty=y"
{
"locations": [
{
"publicUrl": "localhost:8080",
"url": "localhost:8080"
}
]
}
# Other usages:
# You can actually use the file id to lookup, if you are lazy to parse the file id.
curl "http://localhost:9333/dir/lookup?volumeId=3,01637037d6"
# If you know the collection, specify it since it will be a little faster
curl "http://localhost:9333/dir/lookup?volumeId=3&collection=turbo"
强制垃圾收集
如果您的系统有许多删除操作,则不会同步回收已删除文件的磁盘空间。有一个后台作业可检查卷磁盘使用情况。如果空白空间大于阈值(默认值为0.3),真空作业将使该卷成为只读卷,仅使用现有文件创建一个新卷,然后打开新卷。如果嫌麻烦或正在做一些测试,请用这种方法清理未使用的空间。
curl "http://localhost:9333/vol/vacuum"
curl "http://localhost:9333/vol/vacuum?garbageThreshold=0.4"
garbageThreshold = 0.4是可选的,并且不会更改默认阈值。您可以使用不同的默认垃圾阈值启动卷主机。此操作并非易事。它将尝试制作.dat和.idx文件的副本,跳过已删除的文件,并切换到新文件,删除旧文件。
预分配卷
一个卷服务一次写入。如果需要增加并发性,则可以预分配大量卷。这是例子。也可以组合所有不同的选项。
# specify a specific replication
curl "http://localhost:9333/vol/grow?replication=000&count=4"
{"count":4}
# specify a collection
curl "http://localhost:9333/vol/grow?collection=turbo&count=4"
# specify data center
curl "http://localhost:9333/vol/grow?dataCenter=dc1&count=4"
# specify ttl
curl "http://localhost:9333/vol/grow?ttl=5d&count=4"
这将生成4个空卷。
删除文件集
# delete a collection
curl "http://localhost:9333/col/delete?collection=benchmark&pretty=y"
检查系统状态
curl "http://10.0.2.15:9333/cluster/status?pretty=y"
curl "http://localhost:9333/dir/status?pretty=y"
Volume Server
这个就是所谓的“Data Node”数据节点,用于挂载磁盘存储文件。Volume Server与Master Server通信,受Master控制。可以动态的增加和减少VolumeServer,这一点比另一个云存储MinIO要强得多。
Volume Server API 可详见 https://github.com/chrislusf/seaweedfs/wiki/Volume-Server-API
Tips:可以使用&pretty = y附加到任何HTTP API,以查看格式化的json输出。
上传文件
curl -F file=@/home/ghostsf/myphoto.jpg http://127.0.0.1:8080/3,01637037d6
{"size": 43234}
返回的大小是存储在SeaweedFS上的大小,有时文件会根据mime类型自动压缩。
直接上传文件
curl -F file=@/home/ghostsf/myphoto.jpg http://localhost:9333/submit
{"fid":"3,01fbe0dc6f1f38","fileName":"myphoto.jpg","fileUrl":"localhost:8080/3,01fbe0dc6f1f38","size":68231}
这个API只是为了方便。主服务器将获得一个文件id并将文件存储到正确的卷服务器。这是一个很方便的API,在分配文件id时不支持不同的参数。
访问文件
curl http://127.0.0.1:8080/3,01637037d6
删除文件
curl -X DELETE http://127.0.0.1:8080/3,01637037d6
查看分块大文件的清单文件内容
curl http://127.0.0.1:8080/3,01637037d6?cm=false
检查卷服务器状态
curl "http://localhost:8080/status?pretty=y"
Filer Server
文件管理器(Filer)可以用来 浏览文件和目录,以及add/delete files, and even browse the sub directories and files,还有检索、重命名等。
配置启动
将filer.toml文件添加到当前目录,或$ HOME / .seaweedfs / 或 / etc / seaweedfs /filer.toml
可以通过以下方式生成
weed scaffold -config=filer -output="."
查看的方式:
weed scaffold -config=filer
filer.toml文件内容:
[leveldb]
enabled = true
dir = "." # directory to store level db files
两种方式启动:
# assuming you already started weed master and weed volume
weed filer
# Or assuming you have nothing started yet,
# this command starts master server, volume server, and filer in one shot.
# It's strictly the same as starting them separately.
weed server -filer=true
管理文件
# Basic Usage:
//create or overwrite the file, the directories /path/to will be automatically created
POST /path/to/file
//get the file content
GET /path/to/file
//create or overwrite the file, the filename in the multipart request will be used
POST /path/to/
//return a json format subdirectory and files listing
GET /path/to/
Accept: application/json
# options for POST a file:
// set file TTL for Cassandra or Redis filer store.
POST /path/to/file?ttl=1d
// set file mode when creating or overwriting a file
POST /path/to/file?mode=0755
列出目录下的文件
这仅适用于嵌入式文件管理器。
一些文件夹可能非常大。为了有效地列出文件,我们使用非传统方式来迭代文件。每个分页都提供一个“ lastFileName”和一个“ limit = x”。文件管理器在O(log(n))时间中找到“ lastFileName”,并检索接下来的x个文件。
List files under a directory
This is for embedded filer only.
Some folder can be very large. To efficiently list files, we use a non-traditional way to iterate files. Every pagination you provide a "lastFileName", and a "limit=x". The filer locate the "lastFileName" in O(log(n)) time, and retrieve the next x files.
curl "http://localhost:8888/javascript/?pretty=y&lastFileName=new_name.js&limit=2"
{
"Directory": "/javascript/",
"Files": [
{
"name": "report.js",
"fid": "7,0254f1f3fd"
}
]
}
删除
删除文件
> curl -X DELETE http://localhost:8888/path/to/file
删除文件夹
// recursively delete all files and folders under a path
> curl -X DELETE http://localhost:8888/path/to/dir?recursive=true
// recursively delete everything, ignoring any recursive error
> curl -X DELETE http://localhost:8888/path/to/dir?recursive=true&ignoreRecursiveError=true
// For Experts Only: remove filer directories only, without removing data chunks.
// see https://github.com/chrislusf/seaweedfs/pull/1153
> curl -X DELETE http://localhost:8888/path/to?recursive=true&skipChunkDeletion=true
说明
Filer具有连接到Master的持久客户端,以获取所有卷的位置更新。没有回调来查找卷ID位置。官方说明参见:https://github.com/chrislusf/seaweedfs/wiki/Directories-and-Files#architecture
mount挂载
weed mount 功能需要配合 Filer 才能使用,这样可以在服务器上用命令行操作文件。支持的操作如下:
- file read / write
- create new file
- mkdir
- list
- remove
- rename
- chmod
- chown
- soft link
- display free disk space
详见:https://github.com/chrislusf/seaweedfs/wiki/Mount
Amazon S3 API
为了与Amazon S3 API兼容,提供了单独的weed s3命令。与在云上操作文件相比,这在读取或写入文件时提供了更快的访问权限。
weed s3将启动无状态网关服务器,以将Amazon S3 API桥接到SeaweedFS Filer。为了方便起见,weed server -s3将启动主服务器,卷服务器,文件管理器和S3网关。
每个存储桶都存储在一个集合中,并且默认情况下映射到文件夹/ buckets / <bucket_name>。
通过删除整个集合,可以有效地删除存储桶。
当前,支持以下API。
// Object operations
* PutObject
* GetObject
* HeadObject
* CopyObject
* DeleteObject
* ListObjectsV2
* ListObjectsV1
// Bucket operations
* PutBucket
* DeleteBucket
* HeadBucket
* ListBuckets
// Multipart upload operations
* NewMultipartUpload
* CompleteMultipartUpload
* AbortMultipartUpload
* ListMultipartUploads
* CopyObjectPart
0x06 异步备份
异步复制到另一个Filer
应该有两个Seaweed文件系统正在运行,可能跨数据中心运行。每个服务器都应具有其文件服务器,主服务器和卷服务器。

详见:https://github.com/chrislusf/seaweedfs/wiki/Async-Replication-to-another-Filer
备份到云
诸如Amazon S3,Google Cloud Storage,Azure,Backblaze B2等云存储选项非常适合备份。
Filer中的每个文件更改都会触发通知发送到消息队列。weed replicate过程将从消息队列中读取,读取实际文件内容,然后将更新发送到云接收器。
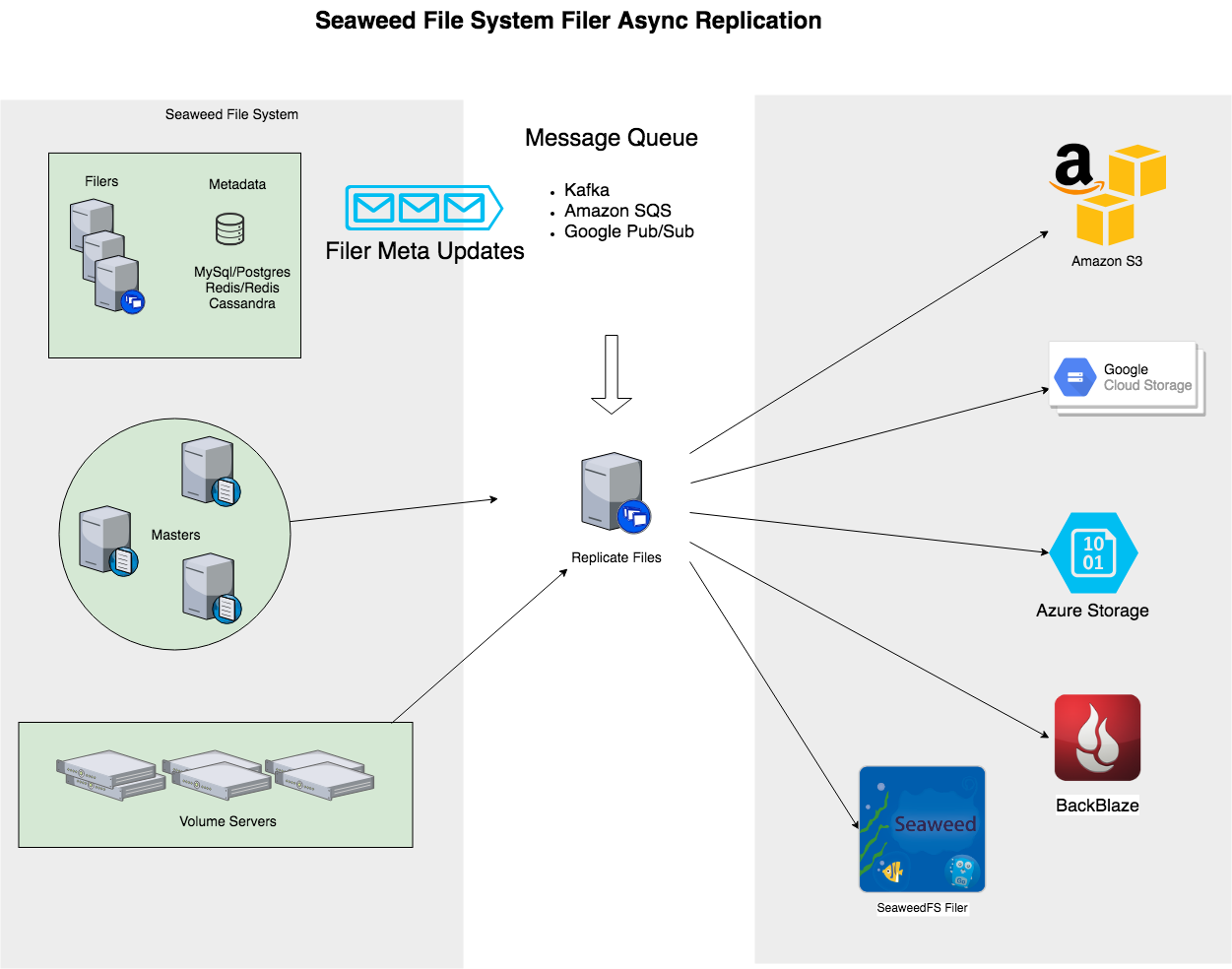
详见:https://github.com/chrislusf/seaweedfs/wiki/Backup-to-Cloud
0x07 进阶
复写配置
SeaweedFS可以支持复制。复制不是在文件级别而是在卷级别实现的。
怎么用?
-
start weed master, and optionally specify the default replication type
./weed master -defaultReplication=001 -
start volume servers as this:
./weed volume -port=8081 -dir=/tmp/1 -max=100 -mserver="master_address:9333" -dataCenter=dc1 -rack=rack1 ./weed volume -port=8082 -dir=/tmp/2 -max=100 -mserver="master_address:9333" -dataCenter=dc1 -rack=rack1
On another rack,
./weed volume -port=8081 -dir=/tmp/1 -max=100 -mserver="master_address:9333" -dataCenter=dc1 -rack=rack2
./weed volume -port=8082 -dir=/tmp/2 -max=100 -mserver="master_address:9333" -dataCenter=dc1 -rack=rack2
No change to Submitting, Reading, and Deleting files.
复写类型的含义
Note: This subject to change.
| Value | Meaning |
|---|---|
| 000 | no replication, just one copy |
| 001 | replicate once on the same rack |
| 010 | replicate once on a different rack in the same data center |
| 100 | replicate once on a different data center |
| 200 | replicate twice on two other different data center |
| 110 | replicate once on a different rack, and once on a different data center |
| … | … |
So if the replication type is xyz
| Column | Meaning |
|---|---|
| x | number of replica in other data centers |
| y | number of replica in other racks in the same data center |
| z | number of replica in other servers in the same rack |
x,y,z each can be 0, 1, or 2. So there are 9 possible replication types, and can be easily extended. Each replication type will physically create x+y+z+1 copies of volume data files.
大文件处理
为了支持大文件,SeaweedFS支持以下两种文件:
- 块文件。每个块文件实际上只是SeaweedFS的普通文件。
- 块清单。一个带有所有块列表的简单json文件。
更多详见:https://github.com/chrislusf/seaweedfs/wiki/Large-File-Handling
安全配置
weed scaffold -config=security 生成security.toml
security.toml文件示例:
# Put this file to one of the location, with descending priority
# ./security.toml
# $HOME/.seaweedfs/security.toml
# /etc/seaweedfs/security.toml
[jwt.signing]
key = "blahblahblahblah"
# all grpc tls authentications are mutual
[grpc]
ca = "/Users/ghostsf/.seaweedfs/out/SeaweedFS_CA.crt"
[grpc.volume]
cert = "/Users/ghostsf/.seaweedfs/out/volume01.crt"
key = "/Users/ghostsf/.seaweedfs/out/volume01.key"
[grpc.master]
cert = "/Users/ghostsf/.seaweedfs/out/master01.crt"
key = "/Users/ghostsf/.seaweedfs/out/master01.key"
[grpc.filer]
cert = "/Users/ghostsf/.seaweedfs/out/filer01.crt"
key = "/Users/ghostsf/.seaweedfs/out/filer01.key"
[grpc.client]
cert = "/Users/ghostsf/.seaweedfs/out/client01.crt"
key = "/Users/ghostsf/.seaweedfs/out/client01.key"
0x08 各语言的客户端
目前官方提供了足够的Api,各种语言的客户端也都有了。
详见:https://github.com/chrislusf/seaweedfs/wiki/Client-Libraries
0x09 不足与问题
- seaweedfs 采用的是同步式复写有以下几个问题:
-
当在某个volume-server 下线又上线恢复的情况下,没有自动的同步机制
-
同步复写需要等待每个节点都复写成功,效率相对较低
-
虽然节点的上下线会快速通过心跳通知master节点,但是仍然存在一定的延迟,期间Volume-Server在复写的时候可能会出现因为复写已经下线的volume-server导致上传失败的情况
- seaweedfs目前在权限管理方面还相对比较弱,目前仅有一个白名单控制机制,来控制外部的读写权限/恶意删除。
0x0A 遇到问题怎么办
我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=l8th8i96wemk